
SVM is an abbreviation for Support Vector Machine, it is a type of machine learning model. SVM is a supervised machine learning algorithm which can be used for both regression as well as classification problems and all machine learning engineers use SVM.
Here is a tricky situation to understand, so hold your horses and read carefully: ML engineers use SVM to find a hyperplane in a space, which is N-dimensional, that classifies data points clearly.
Hyperplane is a boundary that separates two classes. Data points fall on either side of the boundary and are assigned to different classes. The dimensions of this hyperplane depend on the number of inputs.
So, N-dimensional means number of dimensions.
Here is an example to help you understand the explanation above
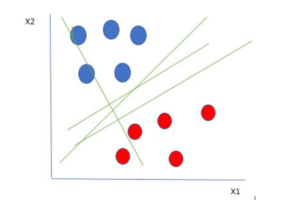
Here we have two variables x1 and x2. One is dependent and the other is independent. For your ease you can think of either the red or blue circle as independent and the other one as dependent.
Hire Machine Learning Engineers
Linearly Separable Data points
From the figure above it’s very clear that there are multiple lines (our hyperplane here is a line because we are considering only two input features x1, x2) that segregates our data points or does a classification between red and blue circles. So how do we choose the best line or in general the best hyperplane that segregates our data points.
Selecting the best hyper-plane:
One reasonable choice as the best hyperplane is the one that represents the largest separation or margin between the two classes.
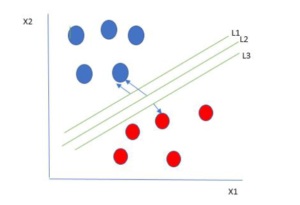
So we choose the hyperplane whose distance from it to the nearest data point on each side is maximized. If such a hyperplane exists it is known as the maximum-margin hyperplane/hard margin. So from the above figure, we choose L2.
Observe this Scenario
Let’s consider an example below to help you understand the concept better.
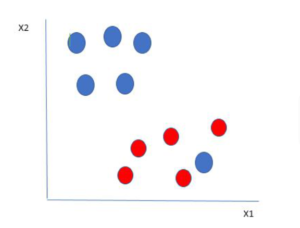
Just like the example above in the picture there are two colors. You can see that one blue ball is in red’s boundary. So this makes the blue ball an outlier. Thus, the SVM classifies it as outlier and the algorithm ignores the data that comes from outlier elements. By classifying the outlier the best possible boundary is set and we get a hyperplane. Thus, maximizing the margin.
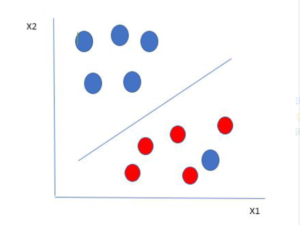
So you can say SVM is prone to outliers.
These data points allow the SVM to find max margin and a plenty is added to either color each time its data point crosses the boundary. Margins in this type of data points are allied soft margins. When a soft margin is set to the data field SVM it tries to lessen the margins.
When data points are on a linear plane they are easy to separate but when they are on a straight line then what is the procedure?
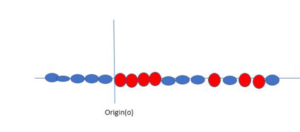
Here SVM becomes smart and creates a new variable and uses the kernel. Keeping the origin o as 0, a point on the line is called XI and other new variable crated is called YI which acts as function of distance from origin.
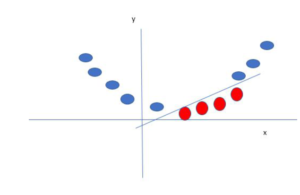
Here is what we get after placing the variables in the formula.
Non-linear functions that are used to create a new variable is called kernel.
Hopefully this gave you a clear understanding of SVM, what it does, and why it is important for machine learning engineers and ML developers.
Read More: Angular and New Era of Web Development


